Importing Postgres databases
This section describes how to import one or more existing PostgreSQL databases inside a brand new CloudNativePG cluster.
The import operation is based on the concept of online logical backups in PostgreSQL,
and relies on pg_dump via a network connection to the origin host, and pg_restore.
Thanks to native Multi-Version Concurrency Control (MVCC) and snapshots,
PostgreSQL enables taking consistent backups over the network, in a concurrent
manner, without stopping any write activity.
Logical backups are also the most common, flexible and reliable technique to perform major upgrades of PostgreSQL versions.
As a result, the instructions in this section are suitable for both:
- importing one or more databases from an existing PostgreSQL instance, even outside Kubernetes
- importing the database from any PostgreSQL version to one that is either the same or newer, enabling major upgrades of PostgreSQL (e.g. from version 10.x to version 14.x)
Warning
When performing major upgrades of PostgreSQL you are responsible for making sure that applications are compatible with the new version and that the upgrade path of the objects contained in the database (including extensions) is feasible.
In both cases, the operation is performed on a consistent snapshot of the origin database.
Important
For this reason we suggest to stop write operations on the source before
the final import in the Cluster resource, as changes done to the source
database after the start of the backup will not be in the destination cluster -
hence why this feature is referred to as "offline import" or "offline major
upgrade".
How it works
Conceptually, the import requires you to create a new cluster from scratch
(destination cluster), using the initdb bootstrap method,
and then complete the initdb.import subsection to import objects from an
existing Postgres cluster (source cluster). As per PostgreSQL recommendation,
we suggest that the PostgreSQL major version of the destination cluster is
greater or equal than the one of the source cluster.
CloudNativePG provides two main ways to import objects from the source cluster into the destination cluster:
-
microservice approach: the destination cluster is designed to host a single application database owned by the specified application user, as recommended by the CloudNativePG project
-
monolith approach: the destination cluster is designed to host multiple databases and different users, imported from the source cluster
The first import method is available via the microservice type, while the
latter by the monolith type.
Warning
It is your responsibility to ensure that the destination cluster can
access the source cluster with a superuser or a user having enough
privileges to take a logical backup with pg_dump. Please refer to the
PostgreSQL documentation on "SQL Dump"
for further information.
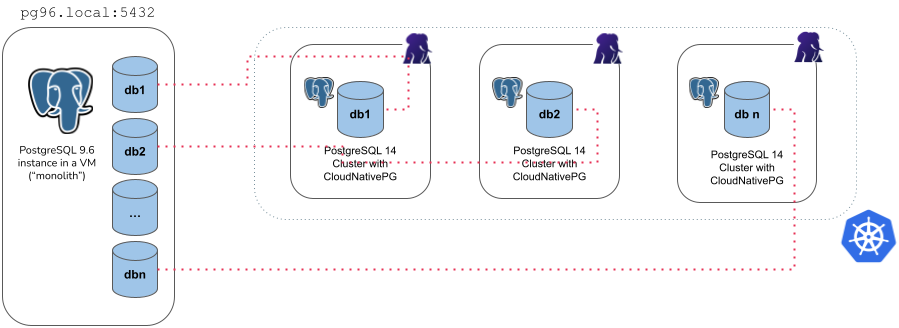
The microservice type
With the microservice approach, you can specify a single database you want to import from the source cluster into the destination cluster. The operation is performed in 4 steps:
initdbbootstrap of the new cluster- export of the selected database (in
initdb.import.databases) usingpg_dump -Fc - import of the database using
pg_restore --no-acl --no-ownerinto theinitdb.database(application database) owned by theinitdb.owneruser - cleanup of the database dump file
- optional execution of the user defined SQL queries in the application
database via the
postImportApplicationSQLparameter - execution of
ANALYZE VERBOSEon the imported database
For example, the YAML below creates a new 3 instance PostgreSQL cluster (latest
available major version at the time the operator was released) called
cluster-microservice that imports the angus database from the
cluster-pg96 cluster (with the unsupported PostgreSQL 9.6), by connecting to
the postgres database using the postgres user, via the password stored in
the cluster-pg96-superuser secret.
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-microservice
spec:
instances: 3
bootstrap:
initdb:
import:
type: microservice
databases:
- angus
source:
externalCluster: cluster-pg96
#postImportApplicationSQL:
#- |
# INSERT YOUR SQL QUERIES HERE
storage:
size: 1Gi
externalClusters:
- name: cluster-pg96
connectionParameters:
# Use the correct IP or host name for the source database
host: pg96.local
user: postgres
dbname: postgres
password:
name: cluster-pg96-superuser
key: password
Warning
The example above deliberately uses a source database running a version of
PostgreSQL that is not supported anymore by the Community, and consequently by
CloudNativePG.
Data export from the source instance is performed using the version of
pg_dump in the destination cluster, which must be a supported one, and
equal or greater than the source one.
Based on our experience, this way of exporting data should work on older
and unsupported versions of Postgres too, giving you the chance to move your
legacy data to a better system, inside Kubernetes.
This is the main reason why we used 9.6 in the examples of this section.
We'd be interested to hear from you should you experience any issues in this area.
There are a few things you need to be aware of when using the microservice type:
- It requires an
externalClusterthat points to an existing PostgreSQL instance containing the data to import (for more information, please refer to "TheexternalClusterssection") - Traffic must be allowed between the Kubernetes cluster and the
externalClusterduring the operation - Connection to the source database must be granted with the specified user
that needs to run
pg_dumpand read roles information (superuser is OK) - Currently, the
pg_dump -Fcresult is stored temporarily inside thedumpsfolder in thePGDATAvolume, so there should be enough available space to temporarily contain the dump result on the assigned node, as well as the restored data and indexes. Once the import operation is completed, this folder is automatically deleted by the operator. - Only one database can be specified inside the
initdb.import.databasesarray - Roles are not imported - and as such they cannot be specified inside
initdb.import.roles
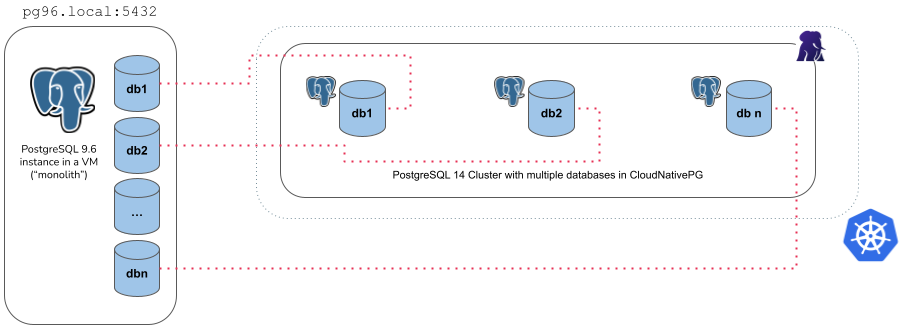
The monolith type
With the monolith approach, you can specify a set of roles and databases you want to import from the source cluster into the destination cluster. The operation is performed in the following steps:
initdbbootstrap of the new cluster- export and import of the selected roles
- export of the selected databases (in
initdb.import.databases), one at a time, usingpg_dump -Fc - create each of the selected databases and import data using
pg_restore - run
ANALYZEon each imported database - cleanup of the database dump files
For example, the YAML below creates a new 3 instance PostgreSQL cluster (latest
available major version at the time the operator was released) called
cluster-monolith that imports the accountant and the bank_user roles,
as well as the accounting, banking, resort databases from the
cluster-pg96 cluster (with the unsupported PostgreSQL 9.6), by connecting to
the postgres database using the postgres user, via the password stored in
the cluster-pg96-superuser secret.
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-monolith
spec:
instances: 3
bootstrap:
initdb:
import:
type: monolith
databases:
- accounting
- banking
- resort
roles:
- accountant
- bank_user
source:
externalCluster: cluster-pg96
storage:
size: 1Gi
externalClusters:
- name: cluster-pg96
connectionParameters:
# Use the correct IP or host name for the source database
host: pg96.local
user: postgres
dbname: postgres
sslmode: require
password:
name: cluster-pg96-superuser
key: password
There are a few things you need to be aware of when using the monolith type:
- It requires an
externalClusterthat points to an existing PostgreSQL instance containing the data to import (for more information, please refer to "TheexternalClusterssection") - Traffic must be allowed between the Kubernetes cluster and the
externalClusterduring the operation - Connection to the source database must be granted with the specified user
that needs to run
pg_dumpand retrieve roles information (superuser is OK) - Currently, the
pg_dump -Fcresult is stored temporarily inside thedumpsfolder in thePGDATAvolume, so there should be enough available space to temporarily contain the dump result on the assigned node, as well as the restored data and indexes. Once the import operation is completed, this folder is automatically deleted by the operator. - At least one database to be specified in the
initdb.import.databasesarray - Any role that is required by the imported databases must be specified inside
initdb.import.roles, with the limitations below:- The following roles, if present, are not imported:
postgres,streaming_replica,cnp_pooler_pgbouncer - The
SUPERUSERoption is removed from any imported role
- The following roles, if present, are not imported:
- Wildcard
"*"can be used as the only element in thedatabasesand/orrolesarrays to import every object of the kind; When matching databases the wildcard will ignore thepostgresdatabase, template databases, and those databases not allowing connections - After the clone procedure is done,
ANALYZE VERBOSEis executed for every database. postImportApplicationSQLfield is not supported