Architecture
For High Availability and Scalability goals, the PostgreSQL database management system provides administrators with built-in physical replication capabilities based on Write Ahead Log (WAL) shipping.
PostgreSQL supports both asynchronous and synchronous streaming replication over the network, as well as asynchronous file-based log shipping (normally used as a fallback option, for example, to store WAL files in an object store). Replicas are usually called standby servers and can also be used for read-only workloads, thanks to the Hot Standby feature.
CloudNativePG supports clusters based on asynchronous and synchronous streaming replication to manage multiple hot standby replicas within the same Kubernetes cluster, with the following specifications:
- One primary, with optional multiple hot standby replicas for High Availability
- Available services for applications:
-rw: applications connect to the only primary instance of the cluster-ro: applications connect to the only hot standby replicas for read-only-workloads-r: applications connect to any of the instances for read-only workloads
- Shared-nothing architecture recommended for better resilience of the PostgreSQL cluster:
- PostgreSQL instances should reside on different Kubernetes worker nodes and share only the network
- PostgreSQL instances can reside in different availability zones in the same region
- All nodes of a PostgreSQL cluster should reside in the same region
Replication
Please refer to the "Replication" section for more information about how CloudNativePG relies on PostgreSQL replication, including synchronous settings.
Connecting from an application
Please refer to the "Connecting from an application" section for information about how to connect to CloudNativePG from a stateless application within the same Kubernetes cluster.
Connection Pooling
Please refer to the "Connection Pooling" section for information about how to take advantage of PgBouncer as a connection pooler, and create an access layer between your applications and the PostgreSQL clusters.
Read-write workloads
Applications can decide to connect to the PostgreSQL instance elected as current primary by the Kubernetes operator, as depicted in the following diagram:
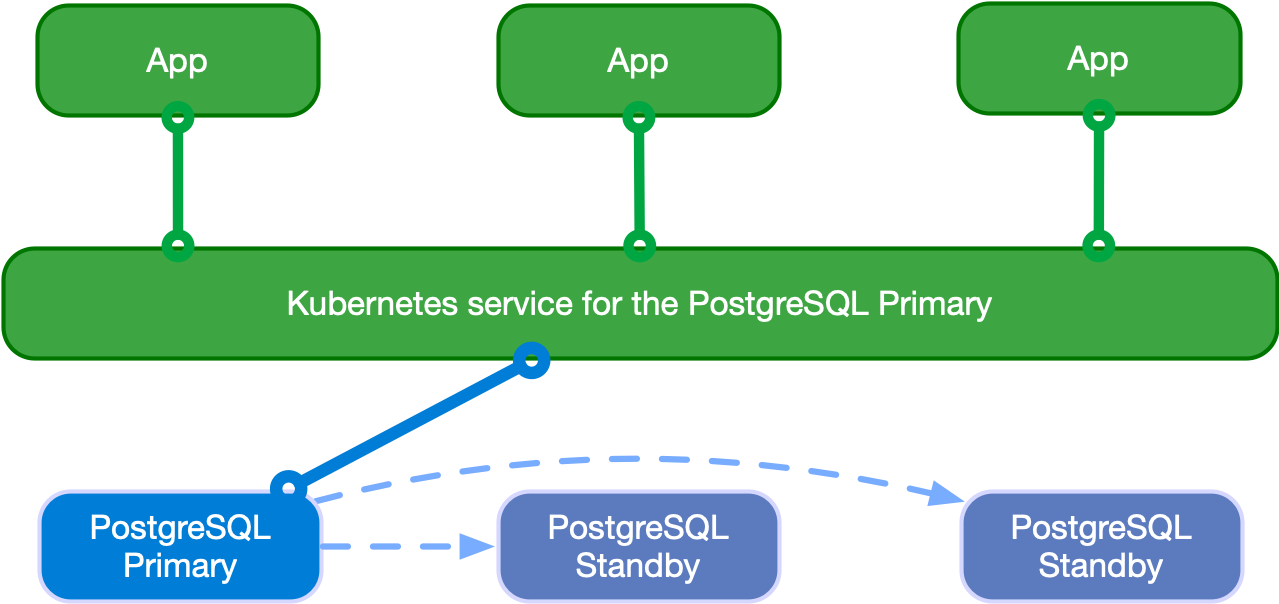
Applications can use the -rw suffix service.
In case of temporary or permanent unavailability of the primary, Kubernetes
will move the -rw service to another instance of the cluster for high availability
purposes.
Read-only workloads
Important
Applications must be aware of the limitations that Hot Standby presents and familiar with the way PostgreSQL operates when dealing with these workloads.
Applications can access hot standby replicas through the -ro service made available
by the operator. This service enables the application to offload read-only queries from the
primary node.
The following diagram shows the architecture:
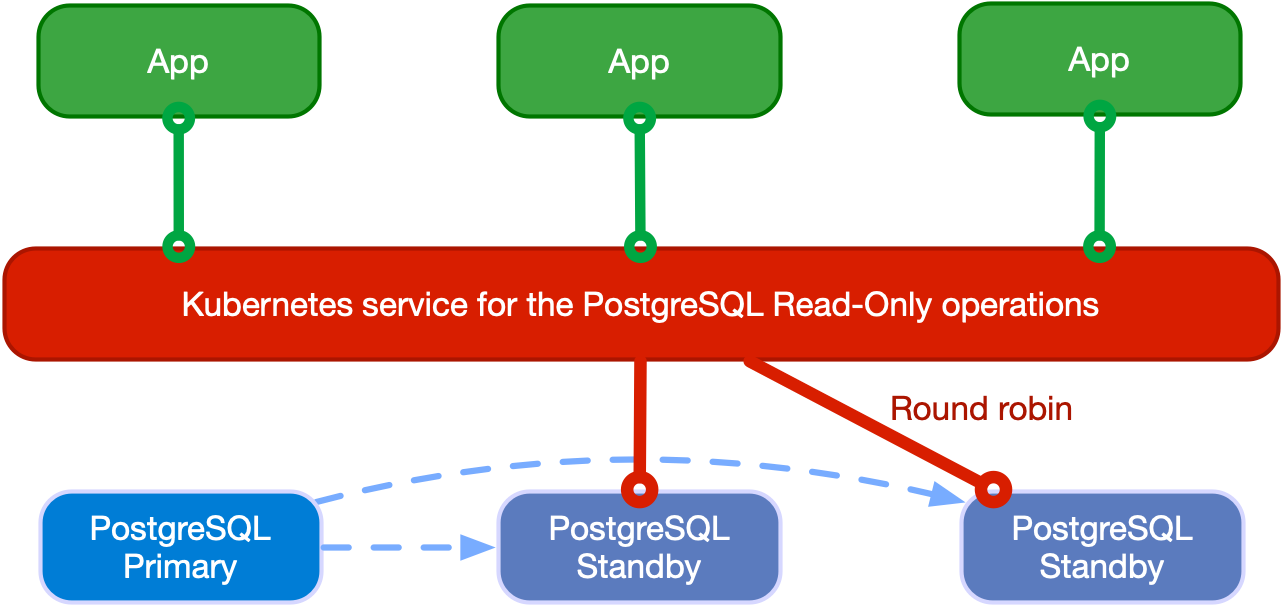
Applications can also access any PostgreSQL instance through the
-r service.
Multi-cluster deployments
Info
CloudNativePG supports deploying PostgreSQL across multiple Kubernetes clusters through a feature called Replica Cluster, which is described in this section.
In a distributed PostgreSQL cluster there can only be a single PostgreSQL instance acting as a primary at all times. This means that applications can only write inside a single Kubernetes cluster, at any time.
Tip
If you are interested in a PostgreSQL architecture where all instances accept writes, please take a look at EDB Distributed Postgres by EDB. For Kubernetes, EDB Distributed Postgres will have its own Operator, expected later in 2022.
However, for business continuity objectives it is fundamental to:
- reduce global recovery point objectives (RPO) by storing PostgreSQL backup data in multiple locations, regions and possibly using different providers (Disaster Recovery)
- reduce global recovery time objectives (RTO) by taking advantage of PostgreSQL replication beyond the primary Kubernetes cluster (High Availability)
In order to address the above concerns, CloudNativePG introduces the concept of a PostgreSQL Replica Cluster. Replica clusters are the CloudNativePG way to enable multi-cluster deployments in private, public, hybrid, and multi-cloud contexts.
A replica cluster is a separate Cluster resource:
- having either
pg_basebackupor fullrecoveryas thebootstrapoption from a defined external source cluster - having the
replica.enabledoption set totrue - replicating from a defined external cluster identified by
replica.source, normally located outside the Kubernetes cluster - replaying WAL information received from the recovery object store
(using PostgreSQL's
restore_commandparameter), or via streaming replication (using PostgreSQL'sprimary_conninfoparameter), or any of the two (in case both thebarmanObjectStoreandconnectionParametersare defined in the external cluster) - accepting only read connections, as supported by PostgreSQL's Hot Standby
Seealso
Please refer to the "Bootstrap" section for more information
about cloning a PostgreSQL cluster from another one (defined in the
externalClusters section).
The diagram below depicts a PostgreSQL cluster spanning over two different Kubernetes clusters, where the primary cluster is in the first Kubernetes cluster and the replica cluster is in the second. The second Kubernetes cluster acts as the company's disaster recovery cluster, ready to be activated in case of disaster and unavailability of the first one.
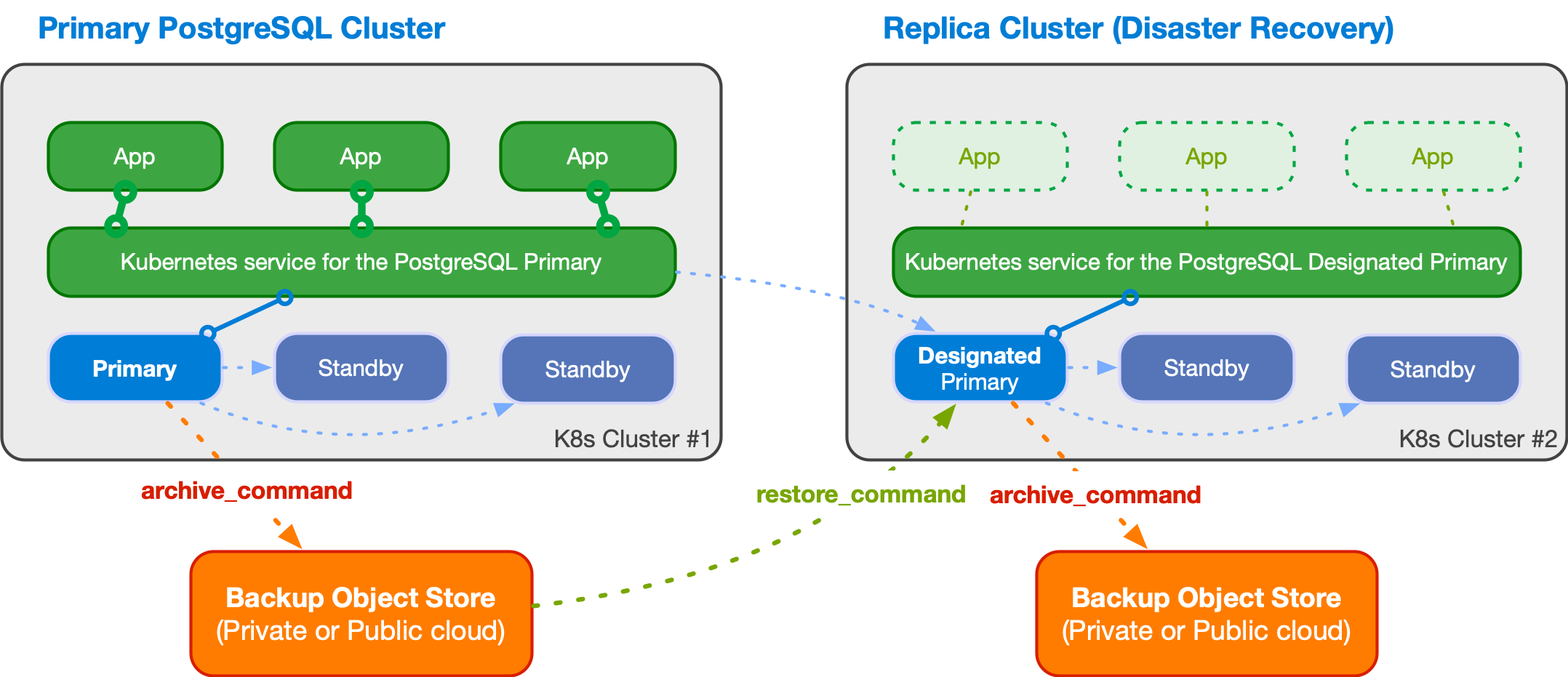
A replica cluster can have the same architecture of the primary cluster. In place of the primary instance, a replica cluster has a designated primary instance, which is a standby server with an arbitrary number of cascading standby servers in streaming replication (symmetric architecture).
The designated primary can be promoted at any time, making the replica cluster a primary cluster capable of accepting write connections.
Warning
CloudNativePG does not perform any cross-cluster switchover or failover at the moment. Such operation must be performed manually or delegated to a multi-cluster/federated cluster aware authority. Each PostgreSQL cluster is independent from any other.
The designated primary in the above example is fed via WAL streaming
(primary_conninfo), with fallback option for file-based WAL shipping through
the restore_command and barman-cloud-wal-restore.
CloudNativePG allows you to define multiple replica clusters. You can also define replica clusters with a lower number of replicas, and then increase this number when the cluster is promoted to primary.
Replica clusters
Please refer to the "Replica Clusters" section for more information about physical replica clusters work and how you can configure read-only clusters in different Kubernetes cluster to improve your global disaster recovery and HA strategy.